O que explica tamanhos erros? No que diz respeito ao tempo, são fáceis de explicar: este modelo de linguagem vai buscar informação recolhida em 2021, pelo que "não tem conhecimento do que se passa na atualidade". É, por isso, inútil perguntar quem serão os líderes atuais dos partidos portugueses com representação parlamentar: a resposta estará datada.
Quanto aos restantes erros, algumas vezes grosseiros, outras vezes subtis, a resposta já pode ser mais complexa de perceber. Por isso, pedimos ajuda a um especialista e criamos este "explicador", para tirar, de uma vez por todas, todas as suas dúvidas sobre esta ferramenta. Não, não a use para fazer batota num exame ou escrever uma canção... pode não correr bem.
Afinal, o que é o ChatGPT, de que tanta gente fala?
“É um modelo estatístico de linguagem”, explica Arlindo Oliveira, professor do Instituto Superior Técnico, investigador e especialista em inteligência artificial.
É baseado no Generative Pre-Training Transformer 3, ou GPT3, um modelo de linguagem com pouco mais de dois anos que “aprende” e produz texto semelhante ao humano. Trocando por “miúdos”, “é um modelo estatístico de linguagem que foi treinado para prever qual é a próxima palavra numa sequência de palavras”, explica o especialista. Ou seja, não passa de um modelo linguístico de aprendizagem automática. Não é uma bola de cristal nem um "Google" com toda a sabedoria do mundo... para já.
Para conseguir “gerar saídas mais agradáveis, preferidas pelos seres humanos”, o ChatGPT, lançado no final do ano passado, usou algoritmos mas também “um conjunto de pessoas”, que analisaram resultados e “escolheram os melhores”, num processo designado de aprendizagem por reforço baseada em referências humanas (ou Reinforcement Learning from Human Feedback - RLHF).
A que fontes recorre?
Mas... a que fontes vai o ChatGPT "beber" a informação que debita?
“O GPT-3 foi treinado num conjunto muito vasto de textos, que inclui centenas de milhares de livros, praticamente toda a Internet, Wikipédia…”, diz o professor. “Só para termos uma ideia, se uma pessoa fosse ler todos os textos que foram usados para treinar o GPT-3 demoraria cinco mil anos a ler, 24 horas por dia”, explica.
O ChatGPT é o único do género?
Nem por isso.“Há muitos modelos de linguagem neste momento”, relembra Arlindo Oliveira que, no entanto, explica o eventual sucesso deste em relação a outros: o já falado fator “agradável”. “O ChatGPT foi treinado para que as respostas sejam particularmente agradáveis, que os seres humanos gostem delas”, reforça. Como também foi “disponibilizado publicamente” tornou-se “muito popular” entre os utilizadores mais comuns.
Podemos confiar no que escreve?
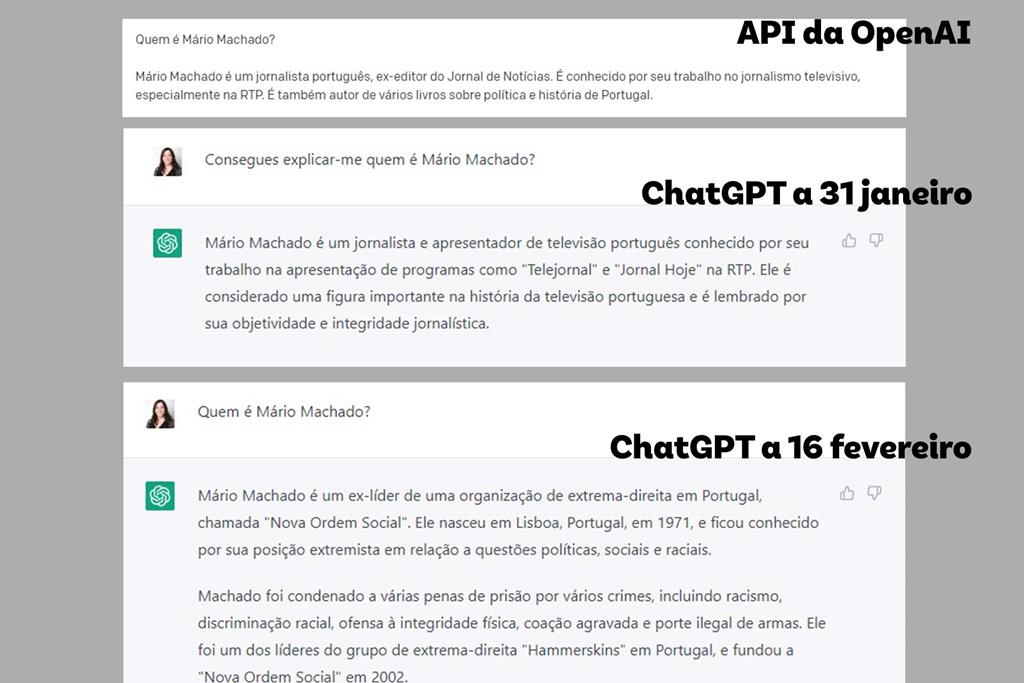
Quem já usou a Internet sabe que nem tudo o que se escreve online é factual... E, se já experimentou usar o ChatGPT (como fizemos neste artigo), já se deparou, certamente, com respostas sem grande sentido.
Podemos, então, confiar no que nos "diz"? Arlindo Oliveira reitera que não. "Como disse, é um modelo estatístico que gera texto plausível. Se fizermos perguntas relativamente genéricas, como 'o que é a democracia?' ou "qual a diferença entre esquerda e direita?', ele dá texto plausível, razoável, provavelmente estará correto em muitos casos", admite. Quando começamos a falar em pessoas a veracidade já será menos provável. "Depende um bocadinho. Se houver muitos e muitos textos sobre a pessoa em particular, provavelmente é suficiente para ele gerar saídas concretas e específicas".
E nem Arlindo escapa a este fenómeno. "As minhas filhas perguntaram sobre mim e ele inventou uma série de coisas, que eu era professor em Coimbra e mais umas coisas falsas", diz. "Por exemplo, inventou artigos científicos que não existem, etc. O sistema é puramente estatístico", reforça.
Ou seja, o que o ChatGPT "diz" não se "escreve"... "Estes modelos geram textos plausíveis, textos estatisticamente prováveis ou plausíveis... mas não são necessariamente corretos".
Isto pode mudar no futuro, até porque o sistema está sempre a aprender. "Há-de haver versões posteriores a este sistema que vão estar mais ancoradas em bases de dados factuais e, que provavelmente, também serão corretos. Mas, neste momento, o modelo é um modelo puramente estatístico, cujo objetivo e cuja função é gerar textos razoáveis e plausíveis, não necessariamente factualmente corretos".
Volta ao seu exemplo. "Eu ser professor em Coimbra... é plausível, porque eu até sou professor em Lisboa, mas não é correto. Não há muita informação, por isso ele inventou umas coisas", salienta. O fenómeno até tem um nome: alucinar. "O sistema alucina quando vê coisas que são razoavelmente plausíveis, mas não são factualmente corretas".
Podemos esperar melhorias?
Arlindo adianta que "está em produção o GPT-4", um "modelo maior, treinado com mais textos". Apesar disso, o investigador não acredita que este modelo "não será assim tão profundamente diferente" do já existente. "Um ChatGPT baseado no GPT-4 não há-de ser assim tão diferente do ChatGPT. Talvez faça menos erros, talvez saiba umas coisas que este não sabe...", diz. Uma mudança poderá estar na atualização. "A parte da informação com que este modelo foi treinado está desatualizada. Não tem as últimas notícias", remata.